The Problem
Right now, our server setup is a bit risky. We’re using ProdBackend1 as the only boss (Manager) and ProdBackend2 as the helper (Worker). The issue is, if ProdBackend1 crashes or takes a nap, the whole system goes offline. There’s no backup plan, so everything stops until the manager is back up. It’s basically a “one-man show” that could break at any moment.
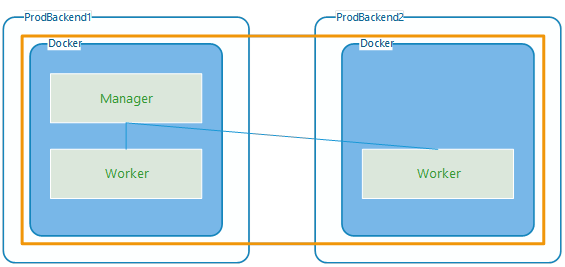
The Goal
Here’s how we’re gonna fix it:
- Specific: We want to add more “bosses” to the team. Instead of just one manager, we’ll have three managers so they can back each other up.
- Measurable: The goal is to keep the system running even if one manager fails. We should see zero downtime for the cluster management.
- Achievable: We just need to add or promote nodes to reach that 3-manager setup, which is the standard “best practice” for this kind of thing.
- Relevant: This makes our app much more reliable. We won’t have to panic every time a server has a hiccup.
- Time-bound: Get this new “safety net” setup ready and tested by this week.
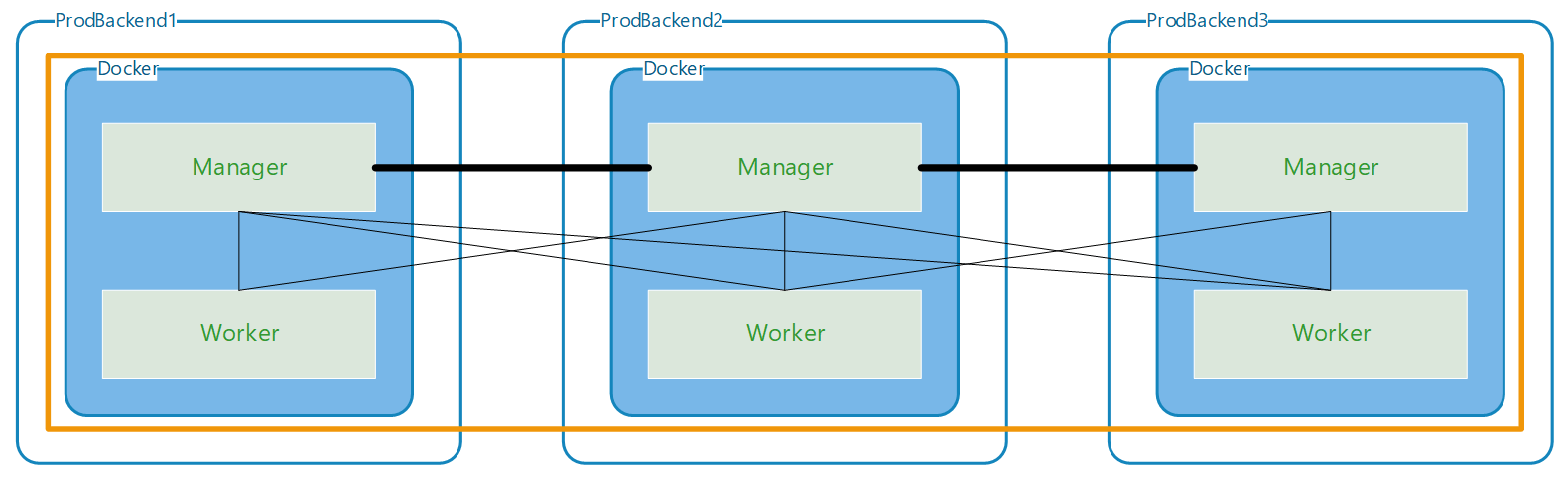
The Bottom Line
“We’re moving from a ‘fragile’ setup to a ‘strong’ one by having three managers. This way, if one goes down, the other two just take over, and nobody even notices there was a problem.”
Proof of Concept (POC)
Currently, our Docker Swarm setup relies on a two-server configuration: ProdBackend1 as the Swarm Manager and ProdBackend2 as a Worker. While this works for basic operations, we identified a major risk: if the manager node goes down, the entire swarm management becomes unavailable. This POC was conducted to demonstrate the vulnerability of our current setup and the benefits of moving to a Three-Manager Quorum.
Phase1: Testing the “Single Point of Failure”
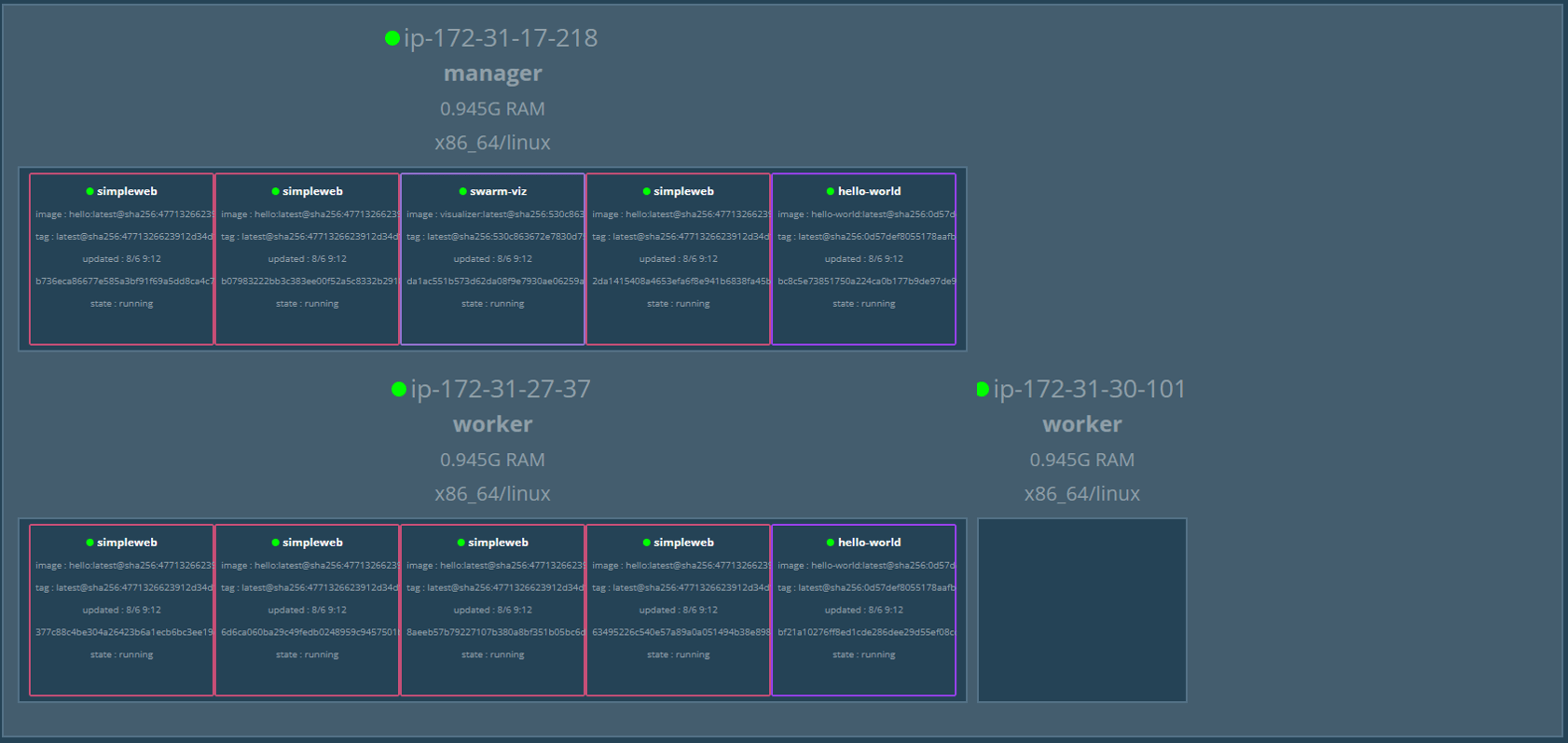
We started with a cluster consisting of one Manager and two Workers. To see how it handles pressure, we deployed three services: Simpleweb (7 replicas), Hello-world (2 replicas), and Swarm-viz.
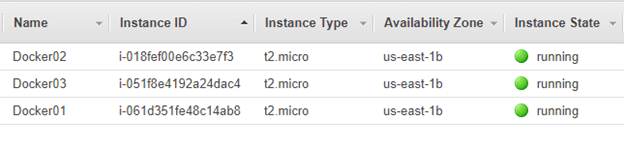
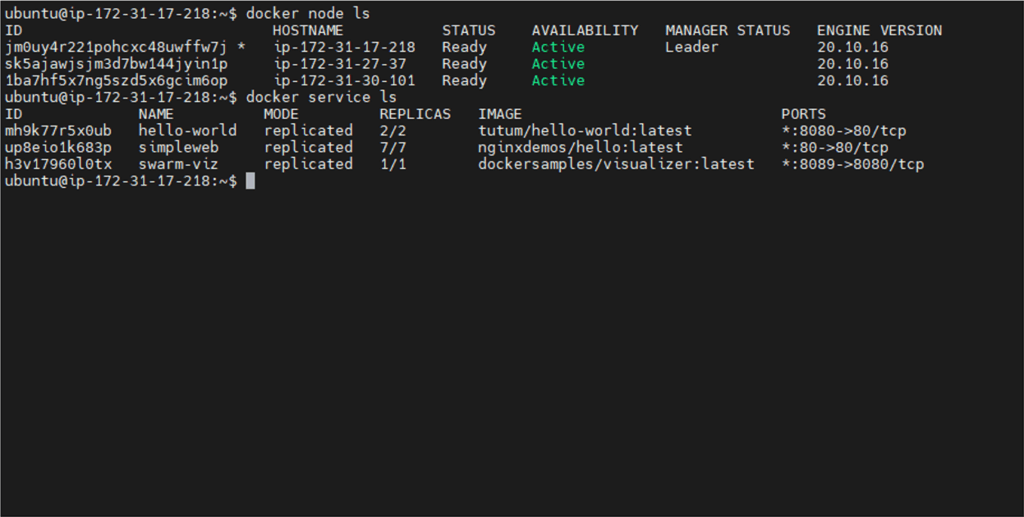
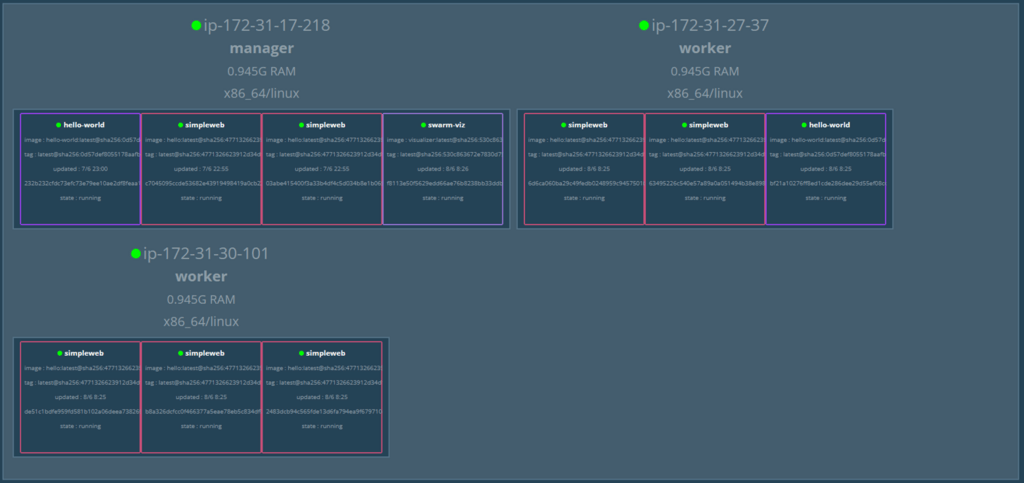
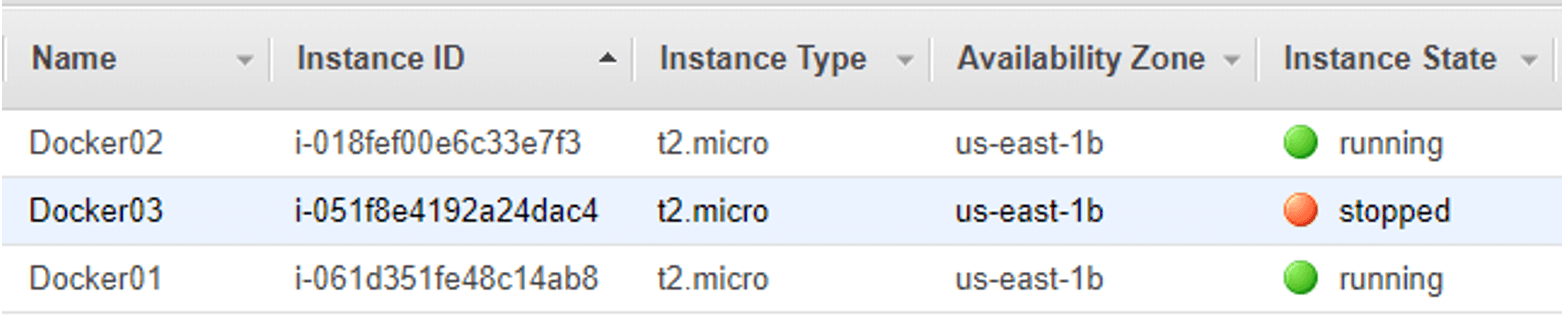
- Docker01
- 1 hello world app
- 2 simple web apps
- 1 swarm-viz app
- Docker02
- 2 simple web apps
- 1 hello world app
- Docker03
- 3 simple web apps
- Scenario A: Worker Node Failure
- Action: We Shut down the worker node ( Docker Server 03)
- Result: The Swarm Manager successfully redistributed all tasks to the remaining available nodes (Docker01 and Docker02).
This proved that the swarm handles worker failures perfectly.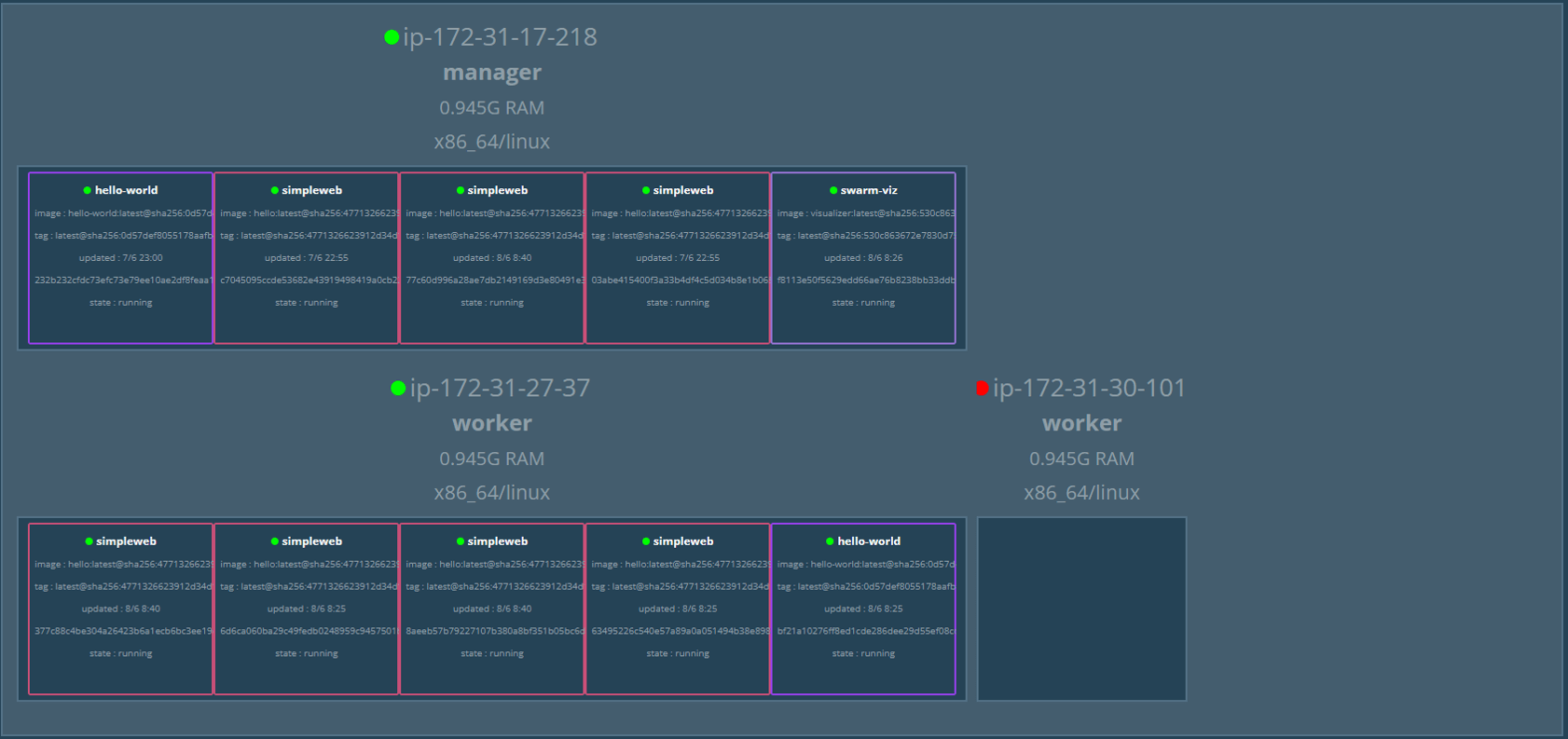
- Bring Up Docker 03

- Action: We Shut down the worker node ( Docker Server 03)
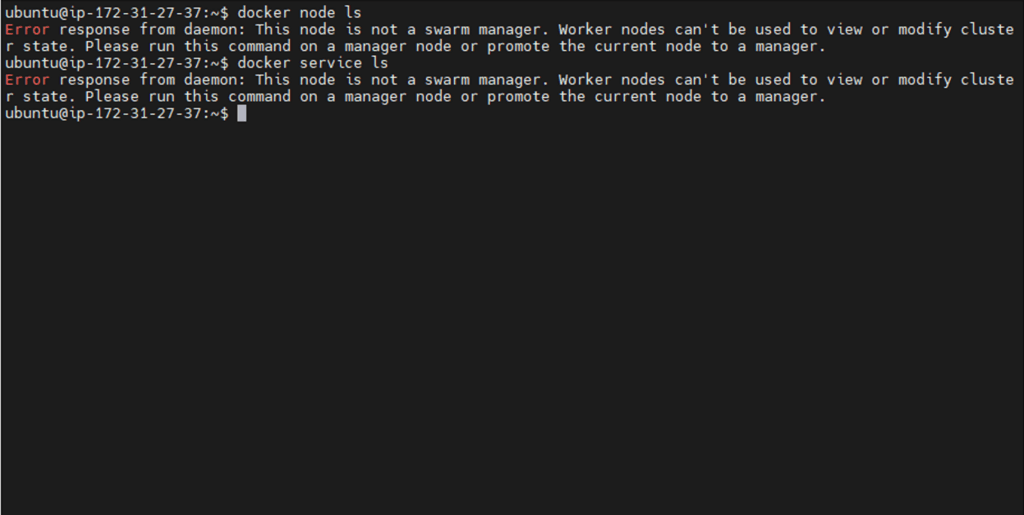
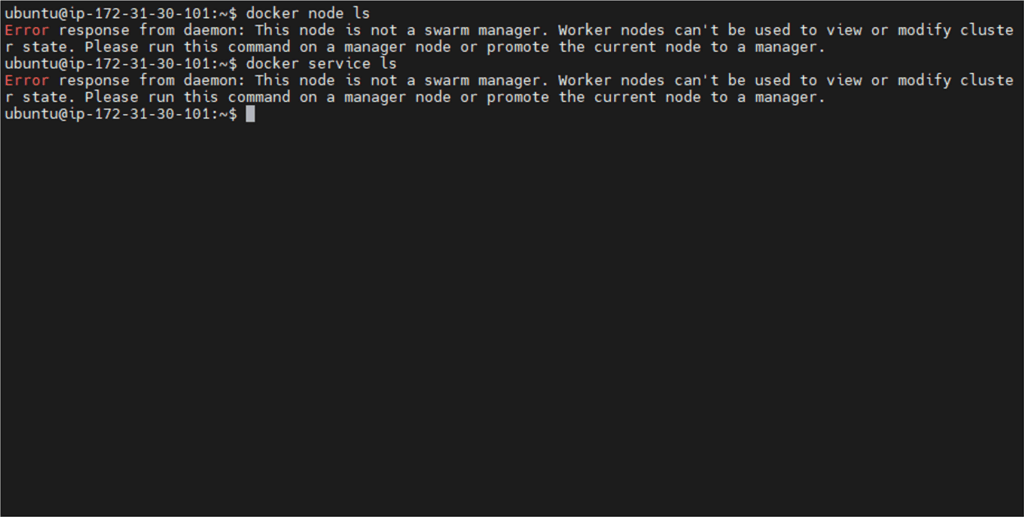
- Scenario B: Manager Node Failure (The “Nightmare” Scenario)
- Action: We simulated a crash on the Manager node (Docker01).

- Result: Even though existing services on Docker02 and Docker03 were still running, no new services could be created or moved. All management operations were paralyzed until Docker01 was brought back online.

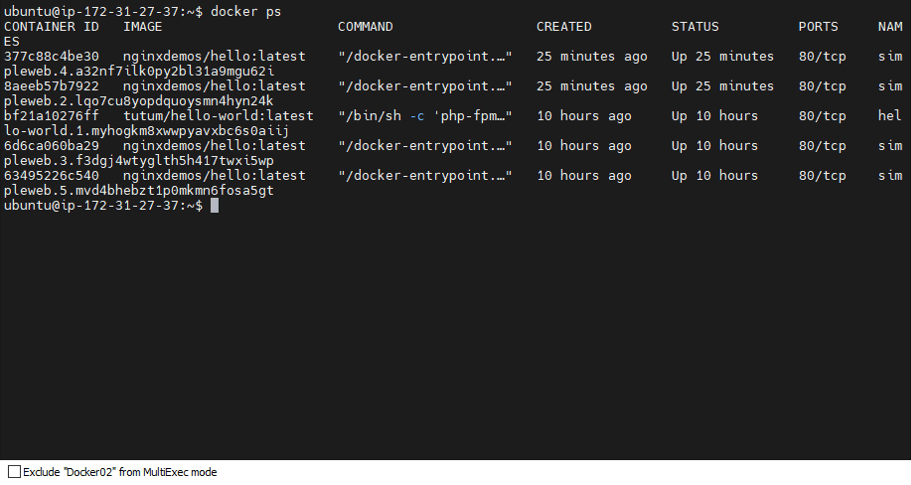
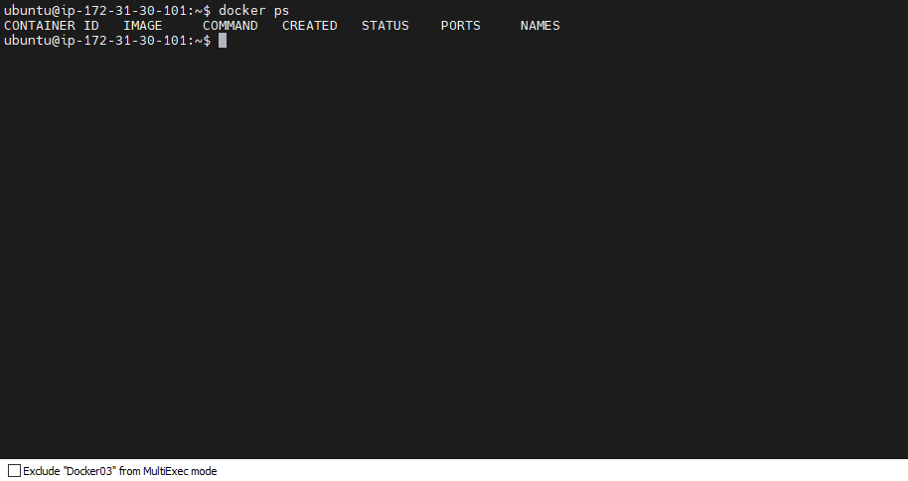 Even Docker03 is running no node moved/created
Even Docker03 is running no node moved/created - Bring Docker01 Back Online

- All node restored on Docker01
- Action: We simulated a crash on the Manager node (Docker01).
Phase 2: Implementing the Solution (Multi-Manager Setup)
To fix the issue found in Phase 1, we upgraded the cluster to a Three-Manager configuration (one Leader and two Followers). This setup uses the Raft Consensus Algorithm to ensure that even if the leader fails, a new one is automatically elected.
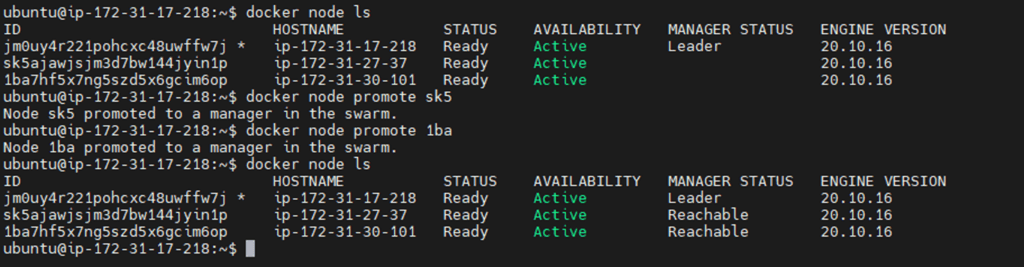
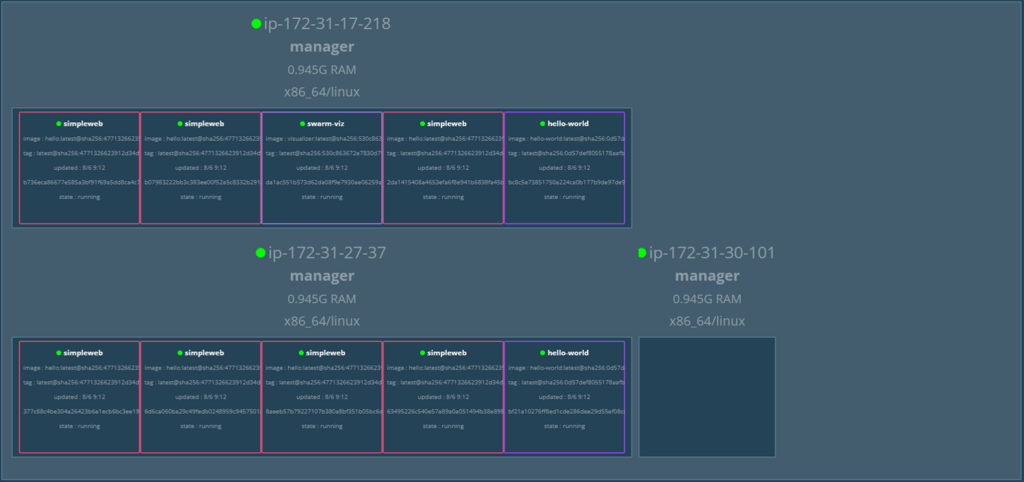
- The “Survival” Test
- Action: We shut down the primary Leader (Docker01).

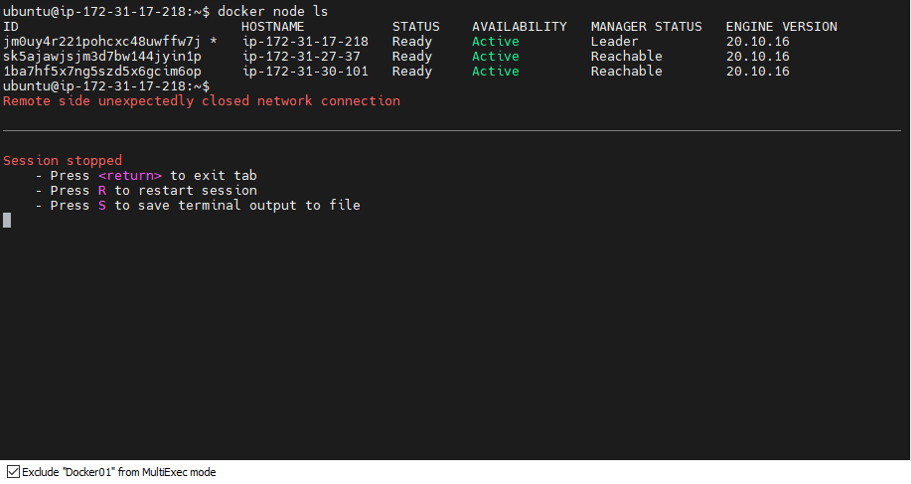
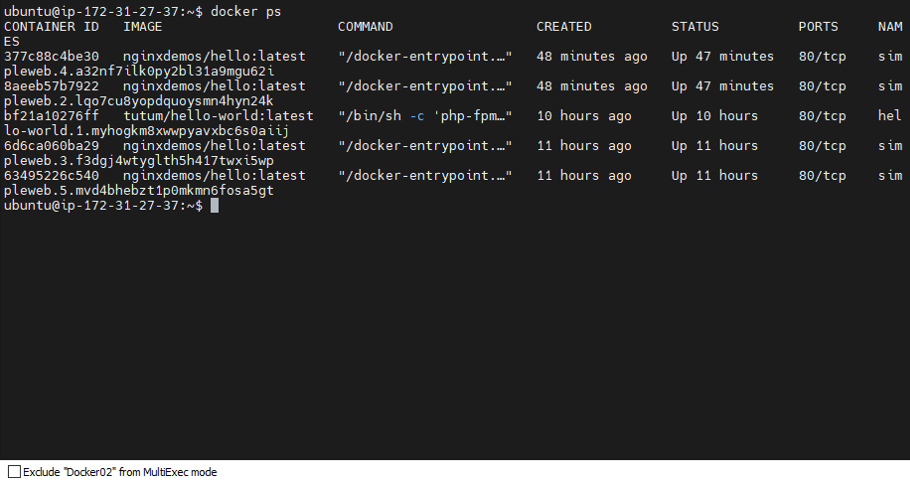
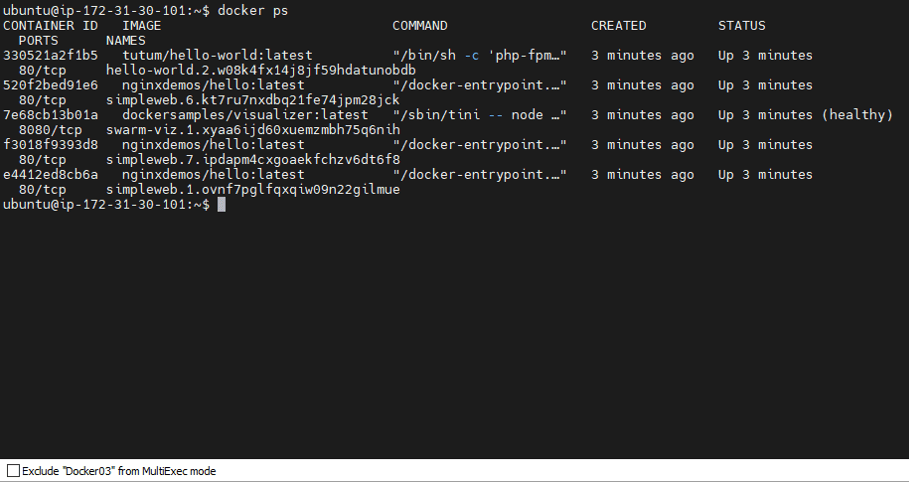
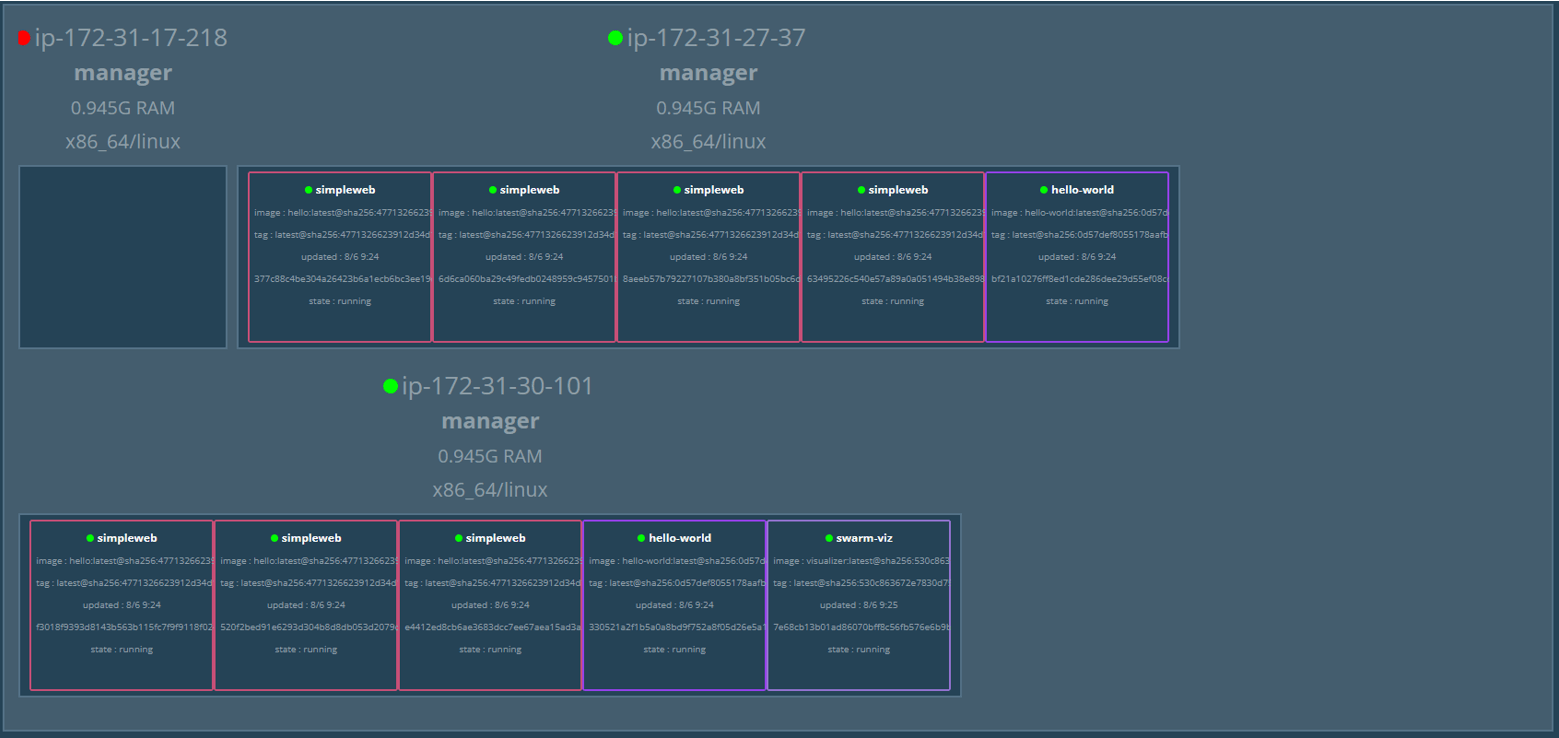
- Result: The cluster didn’t blink! Docker02 was immediately elected as the new Leader, and Docker03 became the Follower.
All services from the failed node were automatically moved to the healthy ones without any manual intervention.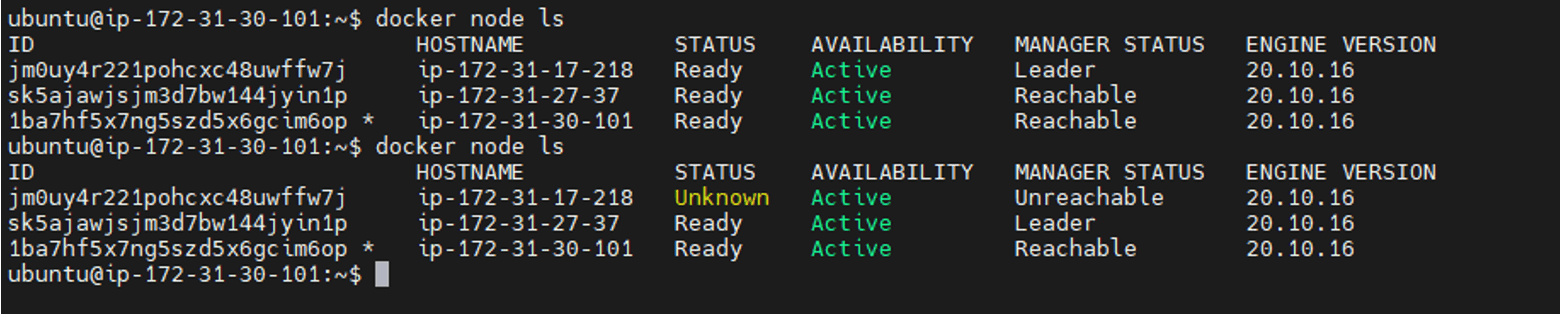
- Action: We shut down the primary Leader (Docker01).
Conclusion & Recommendation
The POC proves that a single-manager setup is a “ticking time bomb” for production. By simply adding more managers to form a quorum:
- We achieve Fault Tolerance: The swarm survives even if one manager goes offline.
- Self-Healing: Services are automatically rescheduled during a manager failure. +1
Recommendation: We should proceed with upgrading our production environment to a minimum of three manager nodes to ensure 100% management availability.



